





3月25日谷歌发布TurboQuant无损压缩算法,直接将大模型键值缓存内存压至1/6、推理速度提8倍,被业内称为“谷歌的DeepSeek时刻”。但很少有人意识到,这场算法突破的影响,远不止AI效率提升这么简单。
谷歌立体标识 / 户外白色背景上的彩色谷歌立体标识
一、从“内存减负”到“规则重构”,TurboQuant的核心突破
在我看来,TurboQuant的价值,绝不是“把内存用得更省”这么表层。它真正打破的,是传统向量量化技术的“效率悖论”——过去企业为了压缩数据,反而要额外存储1-2bit的量化参数,相当于为了省空间先买个更大的箱子,最终得不偿失。
英文推文及中文翻译 / Matthew Prince的X平台推文及中文译文
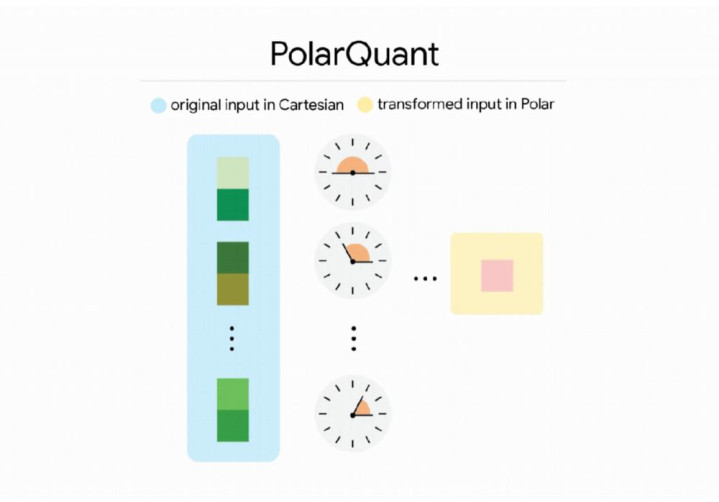
TurboQuant用两步走的思路彻底解决了这个问题:第一步靠PolarQuant极坐标量化,把笛卡尔坐标转成“角度+半径”的极坐标形式,利用角度分布固定的特性,直接省去了数据归一化的内存开销;第二步用1bit无偏误差校正算法QJL,仅用1bit的成本就消除了压缩残留误差,实现真正的无损压缩。
这背后的核心逻辑是,谷歌没有在“压缩比例”上死磕,而是从“压缩的本质需求”出发——企业要的不是数据变小,而是在不损失精度的前提下,用更少内存完成更多计算。TurboQuant做到的,是把“压缩的额外成本”降到了几乎为零。
二、资本市场的过激反应,藏着AI行业的深层焦虑
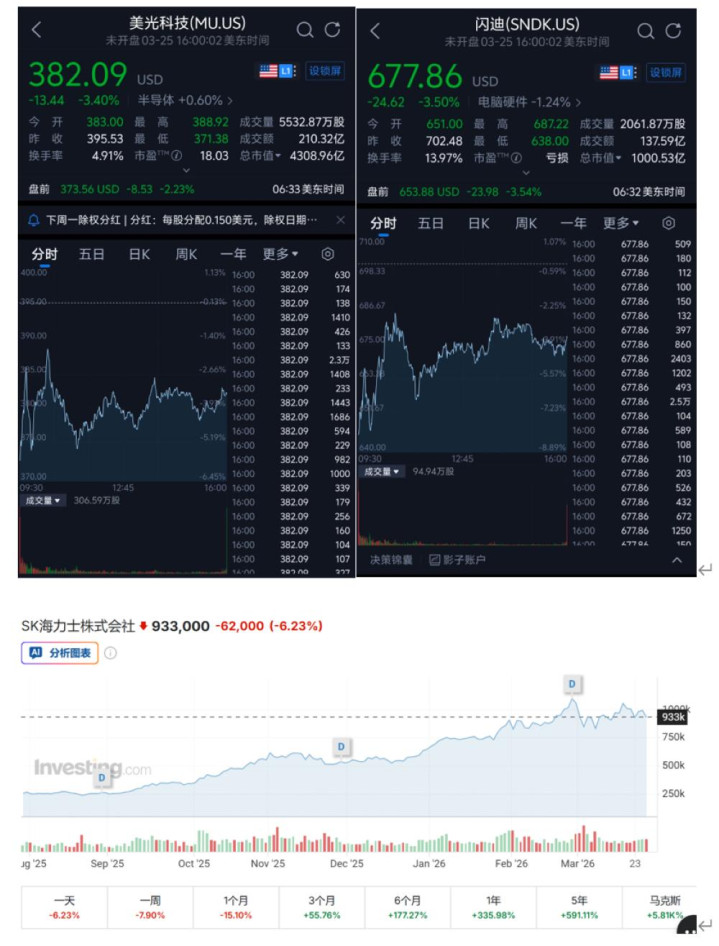
算法突破本该是科技圈的喜事,却直接引发了存储芯片板块的集体跳水:美光盘中跌超5%,收盘仍跌3.4%;闪迪一度跌超7%,市值蒸发超36亿美元;韩股的SK海力士更是收跌6.23%。市场的恐慌,本质是对“AI硬件需求逻辑生变”的担忧。
美光、闪迪、SK海力士股价图 / 三家企业的股价走势及收盘跌幅数据
但在我看来,这种恐慌是典型的“短期情绪过载”。摩根士丹利的分析很到位:TurboQuant只作用于推理阶段的键值缓存,不影响模型训练的高带宽内存(HBM)需求,更不是让存储总需求减少6倍,而是让单GPU的吞吐量提升4-8倍——相同硬件能处理更长的上下文,或者同时服务更多用户。
换句话说,TurboQuant不是“让企业少买芯片”,而是“让企业买的芯片能做更多事”。市场的过度反应,恰恰暴露了当前AI硬件赛道的脆弱:当行业增长高度依赖“硬件堆料”时,任何效率提升的技术突破,都会被解读为“硬件需求的利空”。
三、杰文斯悖论下,AI行业的新机会在哪里?
如果我们把视野拉到1-3年的周期,会发现TurboQuant的真正影响,是重构AI部署的成本曲线。这里要提到一个经济学概念——杰文斯悖论:技术进步带来的效率提升,最终会推动整体需求的增长,而不是减少。
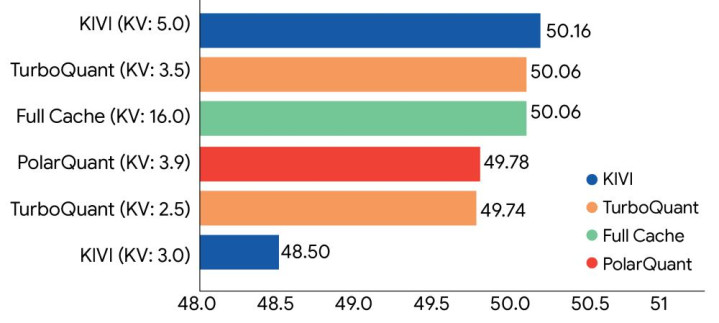
缓存压缩性能对比柱状图 / 多种量化方案的性能得分对比柱状图
放在AI行业里,这个逻辑同样成立:TurboQuant把单次AI查询的成本大幅降低,会让原本只能在云端集群运行的大模型,能迁移到消费级GPU甚至本地硬件上。这意味着AI规模化部署的门槛被彻底拉低,更多过去因成本过高无法落地的应用场景,比如本地长文本处理、边缘端AI推理,都会被激活。
对企业来说,真正的机遇也不是“少买存储芯片”,而是抓住“AI部署门槛降低”带来的新市场:比如为中小企业提供轻量化AI解决方案,或者开发适配长上下文的AI应用,比如法律文档分析、长篇内容创作等。
四、从TurboQuant看AI行业的“效率革命”
在我看来,TurboQuant的发布,标志着AI行业正在从“硬件驱动”转向“效率驱动”。过去几年,AI的进步几乎等同于“用更多GPU训练更大的模型”,但这种模式的边际效益已经在递减——当训练一个大模型要花上亿美元时,行业必须找到更高效的发展路径。

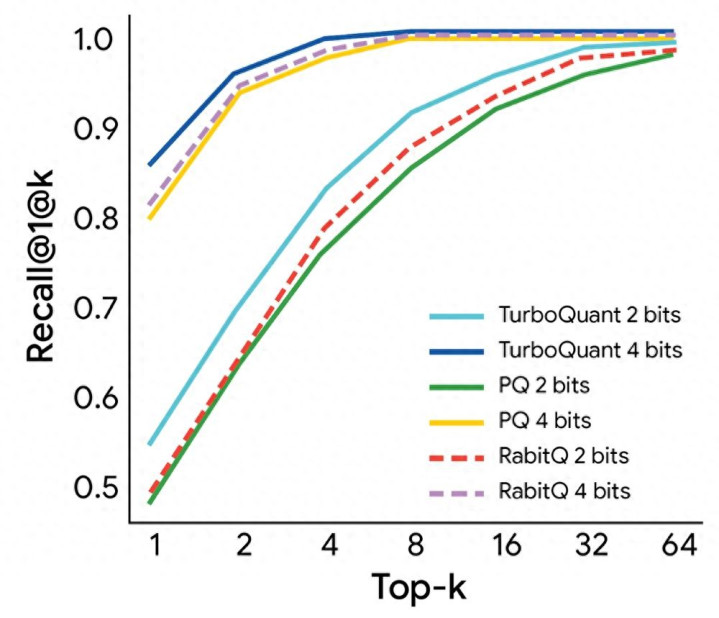
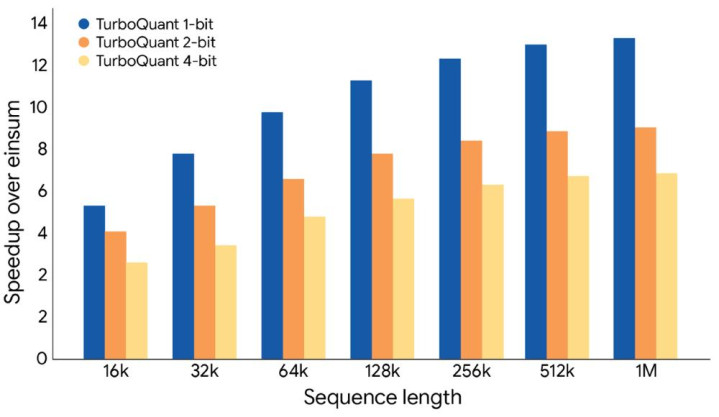
加速效果对比柱状图 / 不同位宽TurboQuant在不同序列长度的加速比
TurboQuant就是这种转向的标志性事件:它证明了,通过算法创新提升现有硬件的利用率,能带来比单纯堆硬件更显著的价值。未来1-2年,我们会看到更多类似的技术突破,比如更高效的注意力机制、更轻量化的模型架构等。
对从业者来说,这意味着行业的核心竞争力正在变化:过去拼的是“能拿到多少GPU”,未来拼的是“能把GPU用得有多好”。而对普通用户来说,这意味着AI应用会变得更便宜、更普及,我们能在更多设备上体验到长上下文AI的能力。
最后我想提出两个问题:你认为TurboQuant会最先激活哪个AI应用场景?存储芯片行业又该如何应对这场效率革命带来的挑战?欢迎在评论区留下你的看法。
PolarQuant工作概念图 / 笛卡尔坐标系转极坐标的量化示意图
红腾网配资提示:文章来自网络,不代表本站观点。






